FIELD REPORT CONVERSATIONAL ANALYTICS
It is 9:40 on a Wednesday night, day three of the monthly close, and Rohan — a financial-planning analyst at a Mumbai-headquartered non-banking financial company with a little over ₹20,000 crore in assets under management — is doing something that, two years ago, would have been impossible at this hour. He is asking the ledger a question.
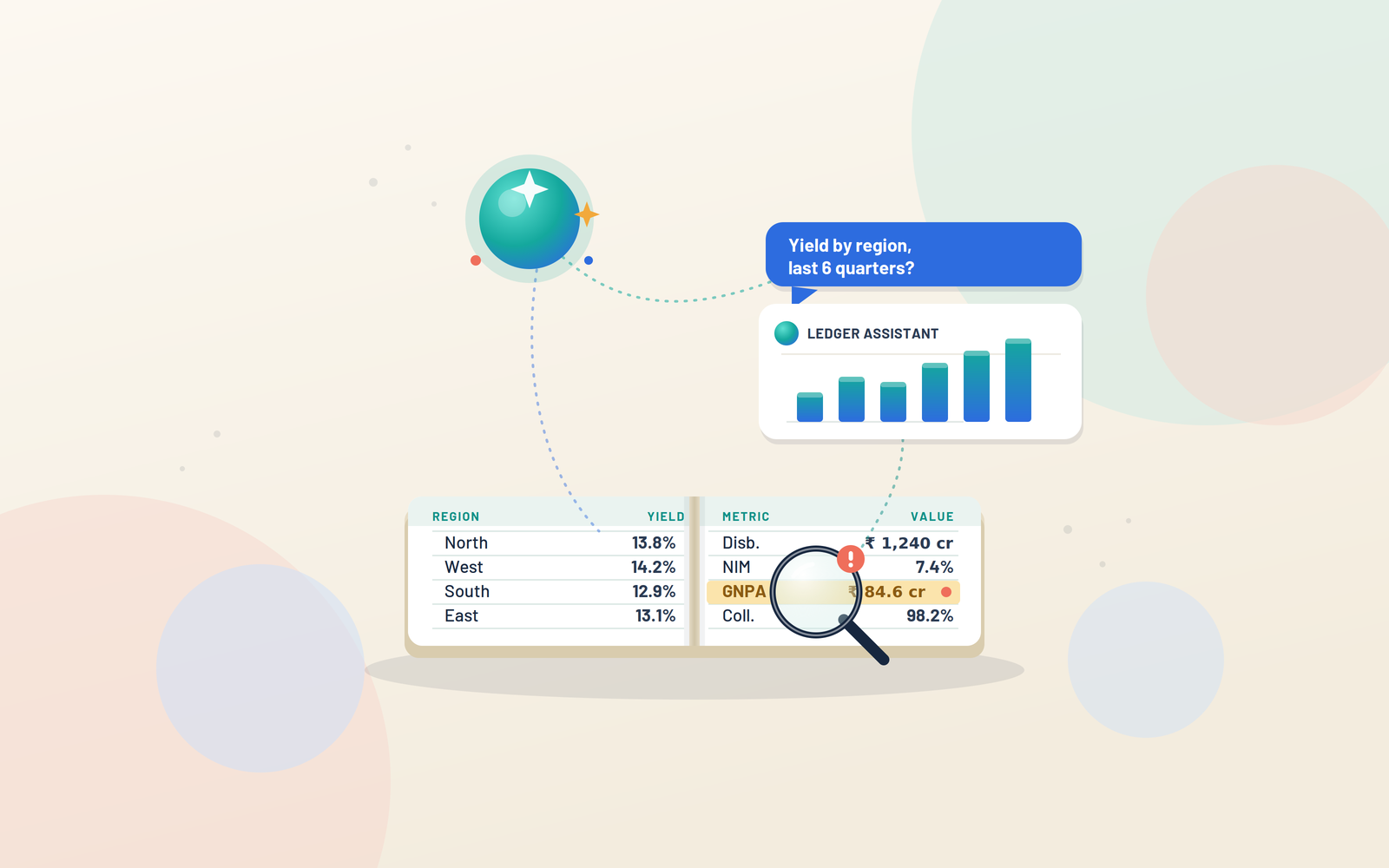
He types it the way he would ask a colleague: “Show me yield on the used-vehicle book by region for the last six quarters, excluding written-off accounts.” A chat panel wired to the company’s financial data warehouse thinks for a moment, then returns a clean table — six quarters, five regions, basis points to one decimal — alongside the exact filters it applied. Elapsed time: roughly forty seconds.
“Before this, that question was a ticket,” Rohan says. “I’d raise a request with the MIS team, it would sit in a queue, and if I was lucky I’d have my numbers in a day and a half. At quarter-end, make it three days.” For an analyst whose job is to have an answer ready before the CFO finishes asking the question, a day and a half was an eternity. “Now I just ask. The hard part isn’t getting the data any more. It’s knowing whether to trust it.”
That last sentence is the whole story.
The bottleneck everyone has
Every finance team in the country sits on a version of the same bottleneck. The people who can write SQL — the MIS or business-intelligence team — are a handful; the people who want numbers are everyone else. Requests pile into a queue, get prioritised by whoever shouts loudest, and come back as a spreadsheet a day or two later, by which point the question has often moved on. During the close, when the controller’s office is reconciling, provisioning and assembling the board pack against a hard deadline, that queue becomes a chokepoint.
The promise of conversational analytics is to make the queue disappear. Put a large language model between the person and the data, let them ask in plain English, and let the machine translate the question into a query. “Ask your ledger anything” is the line on every vendor deck. What made it suddenly plausible for this lender was not the chatbot at all — it was that the unglamorous prerequisite was already in place: a governed data warehouse the finance team trusted, sitting beside an ERP that had taken years to tame. The language model was the last mile, not the journey.
The intern with database access
The most important decision the team made was what not to do. They did not point a language model at the raw general ledger and let it write whatever SQL it liked.
That distinction matters more than any vendor wants to admit. Left to improvise against an unfamiliar schema, large language models fail in characteristic and well-documented ways. They invent table and column names that sound plausible but do not exist; they join tables that happen to share a column and should never be joined; they drop the filters that exclude test data or closed accounts; and they fabricate business metrics that look reasonable but do not match how the business actually defines them. The query runs. It returns a number. The number is wrong, and nothing about it looks wrong.
“An LLM loose on a raw schema is a confident intern with database access. It will hand you a beautifully formatted answer to a question you didn’t ask — and it will never tell you it guessed.”
That line comes from the data lead at the analytics firm that built the system — the implementation partner, who asked to stay unnamed alongside the client. His team’s answer was to put a layer in between. Sitting on top of the data warehouse — not the live ledger — is a semantic layer: a curated catalogue of certified metrics and dimensions where “yield,” “gross NPA,” “cost-to-income” and a few dozen other terms are defined once, in code, the way the controller’s office defines them. The model’s job is narrowed from “write any query you can imagine” to “map this English question onto these approved metrics and filters.”
This is the route the wider industry has converged on as the practical path to production-grade accuracy: pair the model with a semantic layer that encodes the business logic and metric definitions, rather than trusting it to infer them from column names. “Most of the eight months wasn’t spent on the AI,” the partner says. “It was spent curating definitions, watching the query logs, and quietly retiring the answers the model kept getting wrong. The chatbot is the easy twenty per cent.”
What the ledger will now answer
Eight months after go-live, the system handles roughly 3,400 queries a month from about 160 regular users — up from a pilot of fourteen people in FP&A and controllership. The user base has spread well beyond finance: business heads check their own portfolio yields, treasury pulls liquidity positions, regional managers ask about collections without routing through anyone.
The questions that work are the ones that map cleanly to a defined metric over a defined slice: yield by product and region, disbursement trends, cost-to-income by business unit, collection efficiency month-on-month, the ageing of receivables. Roughly seven in ten questions fit that mould, and for those the median time from question to answer has collapsed from about a day and a half to under two minutes. Analysts ask in whatever register they think in — clipped English, Hinglish, half a sentence — and the model copes, because it only has to recognise which certified metric is being reached for, not parse the world.
“It has changed what I do in a day,” Rohan says. “I used to spend the morning waiting for data and the afternoon making it presentable. The waiting is gone, so I spend the time on the part that’s actually mine — why did this number move, not what is the number.”
The questions that do not work are the open-ended ones. Ask “why did margins fall in the South?” and the system can give you the what — margins fell, here is the yield and here is the cost of funds — but the why is still a human’s job. The team tried, early on, to let the model offer narrative explanations and pulled back within weeks; the explanations were fluent and frequently wrong. They learned to sell the tool as a faster way to reach the question, not a way to skip it.
The evening the bad-loan number got better
Then there is the part the vendor decks skip. In the first weeks of the pilot, before the guardrails were fully in place, the system was confidently wrong often enough to frighten the controller’s office.
An internal audit of 200 sampled answers from the early pilot found that around 17 per cent were materially wrong or misleading — not crashes, which are easy to spot, but plausible answers built on a bad join, a missing exclusion, or a metric defined slightly differently than the board pack defines it. “The failures that scared us weren’t the obvious ones,” Meghna says. “They were the answers that were ninety-five per cent right. Those are the ones that get pasted into a slide.”
One incident became the project’s cautionary tale. An analyst asked for the gross NPA trend over the last eight quarters — a figure that goes straight into lender presentations and board material. The system returned a tidy chart. It also, unprompted, pulled in a loan pool that had been sold down and derecognised months earlier, which had the effect of understating gross NPA by roughly 35 basis points in one quarter. The number looked good. It was wrong in the flattering direction — which is the most dangerous direction for a number to be wrong in.
It was caught only because the analyst had been trained to do one thing before trusting any answer: click to see the query the system had run and the row count behind it. The row count was lower than it should have been. A controller’s spot-check did the rest. The fix was structural — gross and net NPA were promoted to certified metrics, hard-pinned to the regulatory definition, so the model can no longer assemble them on the fly.
Governance, the unglamorous half
The guardrails the team added over the following months are, between them, the actual product. Seven of them now do the heavy lifting:
- Certified metrics. Anything that feeds the board, the regulator or an external lender is defined once, in code, and locked. The model selects these numbers; it does not reconstruct them.
- Read-only, always. The system can query the warehouse but can never write back to the ledger. No conversational interface touches a journal entry.
- Transparency by default. Every answer shows its working — the SQL that ran, the tables it touched, the filters it applied, the row count. Verification is one click away, which is the only reason the NPA error was caught.
- A traffic-light trust model. Answers built only from certified metrics are green and self-serve. Ad-hoc questions are amber — useful, but an analyst’s eyes are expected. Anything bound for external or regulatory reporting is red: a human signs off, four-eyes, before it leaves the building.
- Scope fencing for privacy. The model cannot see customer-level personal data unless the user’s role permits it — a choice that maps directly onto India’s data-protection regime.
- A full audit trail. Every question, answer and asker is logged, both to debug the model and to satisfy an AI-governance committee that now reports to the board.
- Disclosure and override. Users are told, plainly, when a number was generated by AI — and a human always has the final say.
That last pair is not housekeeping; it is where the deployment meets the regulator. The Reserve Bank of India’s FREE-AI framework, released in August 2025, builds its expectations for AI in finance around seven principles it calls Sutras — among them that users must know when AI is involved in a determination and that humans retain the authority to override it. The framework pushes AI oversight up to board level, making directors accountable for lapses, and lands alongside the Digital Personal Data Protection Act, whose first phase of enforcement went live in November 2025. For an RBI-regulated lender, conversational analytics over financial data is no longer only an IT decision; it is a governance one. The point was underlined in April 2026, when the finance minister convened the RBI, the technology ministry and bank chiefs to review systemic AI risk across the sector.
By the numbers
What eight months of conversational analytics looked like, by the lender’s own measurement:
|
Metric |
Before |
After |
|
Median time, question to answer (standard metric) |
~1.5 working days |
Under 2 minutes |
|
Ad-hoc requests to the MIS team, per month |
~650 |
~320 |
|
Active users of self-service querying |
14 (pilot) |
~160 |
|
Self-service queries per month |
Near zero |
~3,400 |
|
Share of finance questions answerable by self-service |
— |
~70% |
|
Material-error rate (audited sample of answers) |
~17% (pre-guardrail) |
~3% (post-guardrail) |
|
Errors on certified board / regulatory metrics |
— |
0 |
Source: the lender’s internal measurement over an eight-month deployment.
Figures are illustrative — see editor’s note.
The honest version
Strip away the pitch and what this lender bought is narrower, and more valuable, than “ask your ledger anything.” It is self-service for the seventy per cent of finance questions that are really lookups — fast, cheap, and good enough to free a skilled MIS team for work only humans can do. For the other thirty per cent, it is a faster way to reach the question, not an answer machine.
The thing it quietly gets wrong is the thing every probabilistic system gets wrong: it is most dangerous when it is almost right. A tool that crashed would be safer, because a crash announces itself. An answer that is ninety-five per cent correct, beautifully formatted and confidently delivered will travel — into a slide, a board pack, a lender deck — unless something structural stops it. Here the structural things are certified metrics, a one-click look at the query, and a human gate on anything that leaves the building.
Notes on sourcing. This field report is a composite, drawn from the common pattern of conversational-analytics deployments in Indian finance functions and grounded in the publicly documented behaviour of text-to-SQL systems and current RBI and DPDP guidance. The enterprise, the individuals quoted and the figures are representative and illustrative rather than a record of one named company’s audited results.